
컬렉션(Collection)
컬렉션 프레임워크란
- 객체를 그룹 단위의 데이터로 저장하는 기본적인 자료구조들의 모음
- 자료구조가 내장되어있는 클래스이자 자바에서 제공하는 “자료구조”를 담당하는 “프레임워크”이다
=> 데이터들이 새로이 추가되거나, 삭제가 되거나, 수정이 되는 기능(알고리즘) 들이 이미 정의 되어있는 틀
=> 추가, 삭제, 정렬 등의 기능처리가 간단하게 해결되어 따로 자료구조적 알고리즘을 구현할 필요가 없게 해준다 - java.util 패키지에 포함되어있다
- 인터페이스를 통해 정형화된 방법으로 다양한 컬렉션 클래스를 이용 가능하다
-
다수의 데이터를 그룹으로 묶어 관리할 수 있으므로 프로그래밍이 보다 편리해지고, 코드의 재사용성을 늘릴 수 있다
-
자료구조 : 메모리상에서 자료를 구조적으로 처리하는 방법론
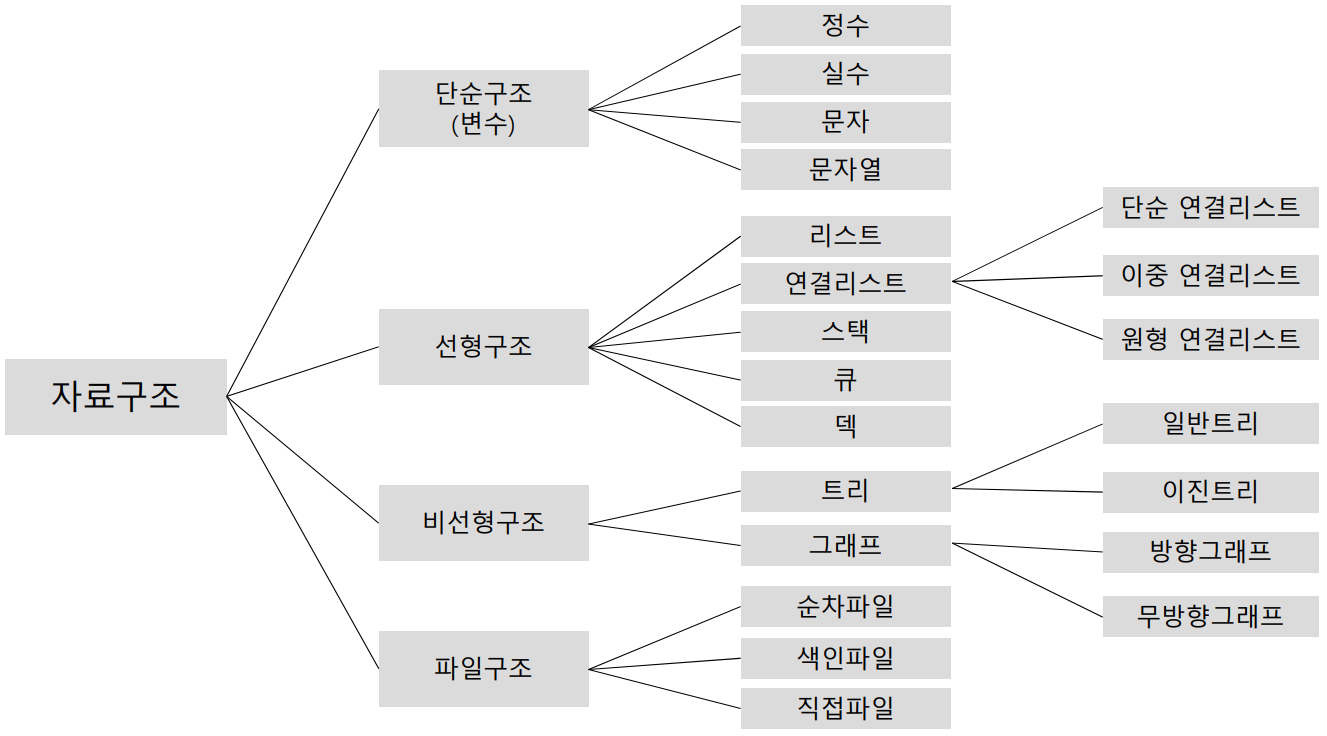
- 프레임워크 : 효율적인 기능들이 이미 정의되어있는 틀(프레임)
[ 배열의 문제점 & 컬렉션의 장점 ]
-
배열의 문제점
- 한번 크기를 지정하면 변경 할 수 없다
- 기록된 데이터에 대한 중간 위치의 추가, 삭제가 불편하다
=> 추가, 삭제할 데이터부터 마지막 기록된 데이터까지 하나씩 뒤로 밀어내고 추가하는 등의 복잡한 알고리즘을 직접 구현해야 함 - 한 타입의 데이터만 저장 가능하다
-
컬렉션의 장점
- 저장하는 크기의 제약이 없다
- 추가, 삭제, 정렬 등의 기능처리가 간단하다
- 여러 타입의 데이터를 저장 가능하다
=> 객체만 저장 가능하기 때문에 필요에따라 기본 자료형에 Wrapper 클래스를 사용하여 저장한다
=> 단, 제네릭 설정을 통해서 한 타입의 데이터들만 저장할 수도 있다
-
결론
- 배열의 단점들을 보완한 것이 컬렉션이라고 볼 수 있다
- 데이터들을 단지 담아만 두고 조회만 할 목적이면 배열을 선택
- 데이터들이 빈번하게 추가, 삭제, 수정 될 것 같다면 컬렉션을 선택
컬렉션의 주요 인터페이스
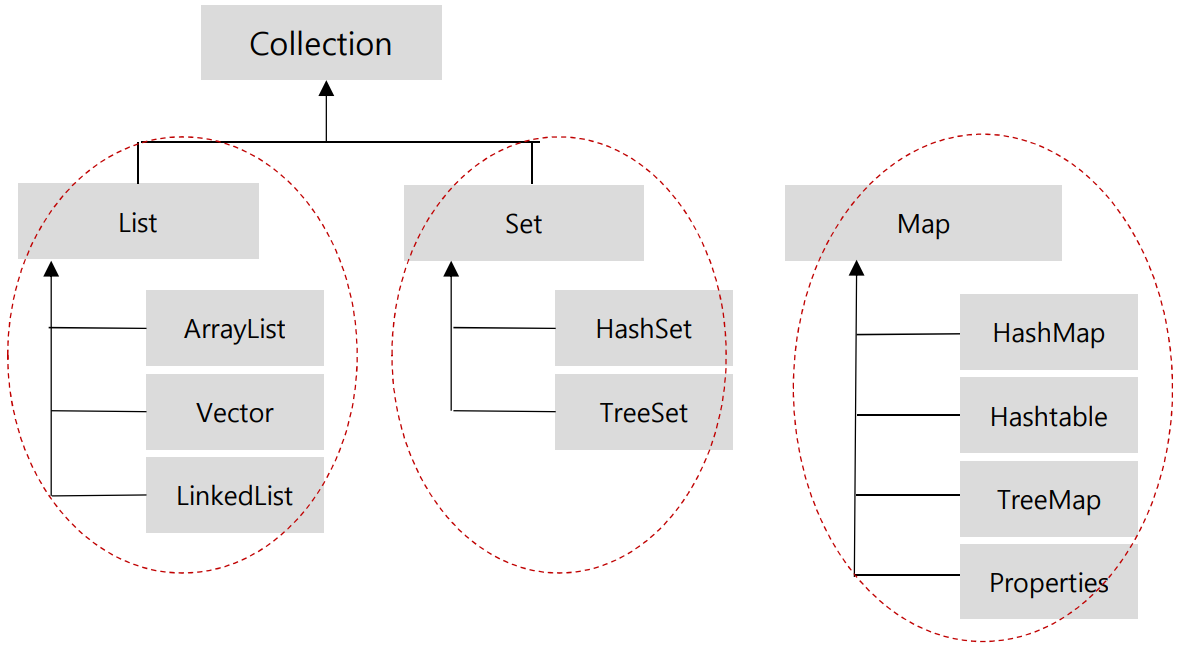
| 인터페이스분류 | 특징 | 구현 클래스 | |
|---|---|---|---|
| Collection | List | 순서를 유지하고 저장 중복 저장 가능 |
ArrayList, Vector, LinkedList |
| Set | 순서를 유지하지 않고 저장 중복 저장 안됨 |
HashSet, TreeSet | |
| Map | 키와 값의 쌍으로 저장 키는 중복 안 됨 값은 중복 저장 가능 |
HashMap, Hashtable, TreeMap, LinkedHashMap, Properties | |
[ List ]
- 자료들을 일렬로 나열한 자료구조
- 객체를 인덱스로 관리함
=> 객체를 저장하면 자동 인덱스가 부여되고 인덱스로 객체를 검색, 삭제할 수 있는 기능을 제공 - 중복해서 객체 저장 가능
-
구현 클래스로 ArrayList와 Vector, LinkedList가 있다
- 주요 메소드
기능 메소드 설명 객체 추가 boolean add(E e) 주어진 객체를 맨 끝에 추가 void add(int index, E element) 주어진 인덱스에 객체를 추가 boolean addAll(Collection<? extends E> c) 주어진 Collection타입 객체를 리스트에 추가 set(int index, E element) 주어진 인덱스에 저장된 객체를 주어진 객체로 바꿈 객체 검색 boolean contains(Object o) 주어진 객체가 저장되어 있는지 여부 E get(int index) 주어진 인덱스에 저장된 객체를 리턴 boolean isEmpty() 컬렉션이 비어 있는지 조사 int size() 저장되어 있는 전체 객체 수 리턴 Iterator<E> iterator() 저장된 객체를 한번씩 가져오는 반복자 리턴 객체 삭제 void clear() 저장된 모든 객체를 삭제 E remove(int index) 주어진 인덱스에 저장된 객체 삭제 boolean remove(Object o) 주어진 객체를 삭제 - 그 외
subList(int index1, int index2): 해당 리스트로부터 index1에서 index2까지의 데이터 값들을 추출해서 새로운 List로 반환시켜주는 메소드
- 그 외
ArrayList
// 기본생성자로 ArrayList 객체 생성
List<기본타입> list = new ArrayList<기본타입>();
// 초기화 (고정된 객체들로 구성된 List를 생성하고자 할 때)
List<String> list = Arrays.asList("Apple", "Banana", "Orange");
- 일반 배열과 같이 인덱스로 객체를 관리
- List의 후손으로 초기 저장용량은 10으로 자동 설정 또는 따로 지정 가능하다 => 객체 생성시 용량을 지정하지 않을경우 10으로 자동 생성된다
- 저장 용량을 초과한 객체들이 들어오면 자동으로 증가된다 (고정도 가능하다)
- 상당히 빠르고 크기를 마음대로 조절할 수 있는 배열이다
- 단방향 포인터 구조로 자료에 대한 순차적인 접근에 강점이 있다
- 동기화(Synchronized)를 제공하지 않는다 => 동기화란 하나의 자원(데이터)에 대해 여러 스레드가 접근하려 할 때, 한 시점에서 하나의 스레드만 사용 가능하도록 하는 것이다
Vector
//기본 생성자
List<E> list = new Vector<E>();
- ArrayList의 구버전이다
- ArrayList와 동일한 내부 구조를 가지고 있다
- 모든 메소드에서 동기화(Synchronized)를 제공한다는 점이 ArrayList와의 차이점이다
- List 객체들 중에서 가장 성능이 좋지 않다
LinkedList
//기본 생성자
List<E> list = new LinkedList<E>();
- 양방향 포인터 구조로 데이터의 삽입, 삭제가 빈번할 경우 빠른 성능을 보장한다
=> 이런경우 ArrayList보다 LinkedList가 더 좋은 성능을 발휘한다 - ArrayList와 사용 방법은 똑같지만 인접 참조를 링크해 체인처럼 관리한다는 점이 다르다
=> 저장된 각 객체마다 자신의 앞, 뒤에 어떤 객체가 있는지를 링크해둔다 - 객체가 중간 인덱스에서 삭제되거나 삽입될 때 바로 앞뒤 링크만 변경되고 나머지 링크는 변경되지 않는다
=> ArrayList에서는 뒤의 객체들의 인덱스가 변경된다 - 스택, 큐, 양방향 큐 등을 만들기 위한 용도로 사용된다
[ Comparable, Comparator을 통한 정렬 ]
| 구분 | Comparable | Comparator |
|---|---|---|
| 패키지 | java.lang | java.util |
| 사용 메소드 | compareTo() | compare() |
| 정렬 | 기존의 정렬기준을 구현하는데 사용 | 그외다른여러기준으로정렬하고자할때사용 |
| 사용법 | 정렬하고자 하는 객체에 Comparable를 상속받고 compareTo() 메소드를 오버라이딩해 기존의 정렬기준을 재정의한다 => 한 개의 정렬만 가능 |
vo 패키지 안에 필요한 정렬 기준에 맞춘 클래스들을 생성하고 Comparator를 상속받아 compare() 메소드를 오버라이딩, 기존의 정렬 기준 재정의 => 여러 개의 정렬 가능 |
- Collections.sort()
Collections.sort(List<T> list): T객체에 Comparable을 상속받아 compareTo 메소드 재정의를 통해 정렬 구현 (한 개의 정렬)Collections.sort(List<T> list, Comparator<T> c): 지정한 Comparator클래스에 의한 정렬 (여러 개의 정렬)
[ Set ]
- 저장 순서가 유지되지 않고 객체를 중복해서 저장 할 수 없다
=> null도 중복을 허용하지 않기때문에 1개의 null만 저장 가능하다 - 인덱스로 관리하지 않기 때문에 인덱스를 매개 변수로 갖는 메소드가 없다
-
구현클래스로 HashSet, LinkedHashSet, TreeSet이 있다
- 주요 메소드
| 기능 | 메소드 | 설명 |
|---|---|---|
| 객체 추가 | boolean add(E e) | 주어진 객체를 맨 끝에 추가 |
| boolean addAll(Collection c) | 주어진 Collection타입 객체를 리스트에 추가 | |
| 객체 검색 | boolean contains(Object o) | 주어진 객체가 저장되어 있는지 여부 |
| boolean isEmpty() | 컬렉션이 비어 있는지 조사 | |
| int size() | 저장되어 있는 전체 객체수를 리턴 | |
| Object[] toArray() | 배열로 반환 | |
| Object[] toArray(Object[] a) | 지정한 배열의 클래스 타입으로 배열로 반환 | |
| Iterator<E> iterator() | 저장된 객체를 한번씩 가져오는 반복자 리턴 | |
| 객체 삭제 | void clear() | 저장된 모든 객체를 삭제 |
| boolean remove(Object o) | 주어진 객체를 삭제 | |
| boolean removeAll(Collection c) | 저장된 모든 객체를 삭제 |
HashSet
Set<E> set = new HashSet<E>();
- 내부적으로 HashMap을 사용한다
- Set에 객체를 저장할 때 hash함수를 사용하여 처리 속도가 빠르다
- 동일 객체 뿐만 아니라 동등객체도 중복하여 저장하지 않는다
=> 저장하려는 객체의 해시코드와 저장된 객체들의 해시코드를 비교해서 같은 값이 없어야 객체를 추가한다
LinkedHashSet
- HashSet과 거의 동일하지만 Set에 추가되는 순서를 유지한다는 점이 다르다
- 추가된 순서, 또는 가장 최근에 접근한 순서대로 접근 가능하다
[ Iterator ]
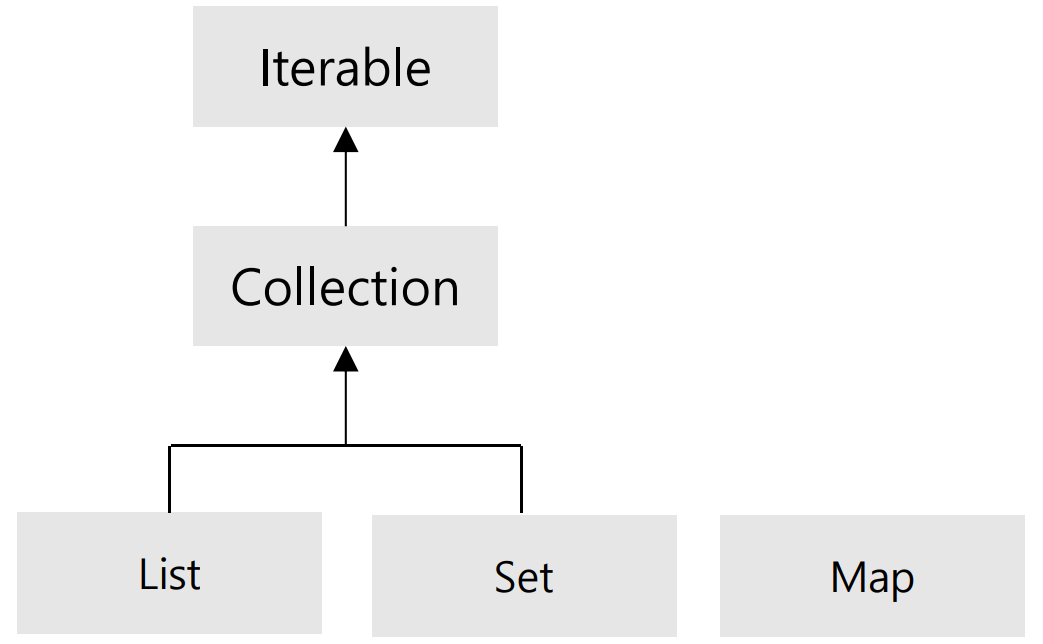
- 컬렉션에 저장된 요소에 접근하는데 사용되는 인터페이스이다
- 비슷한 동작을 하는 것으로 Enumeration, ListIterator 가 있다
=> Enumeration : Iterator의 구버전 => ListIterator : Iterator를 상속받았고 양방향 특징을 가진다 -
위 그림처럼 상속 구조 상 iterator() 메소드는 List와 Set 계열에서만 사용가능하다
=> Map의 경우 Set 또는 List화 시켜서 iterator()를 사용해야 한다 - 주요 메소드
| 구분 | 메소드 | 방향 |
|---|---|---|
| Iterator<E> | boolean hasNext() | 앞에서부터 검색 |
| E next() | ||
| ListIterator<E> | boolean hasNext() | 앞에서부터 검색 |
| E next() | ||
| boolean hasPrevious() | 뒤에서부터 검색 | |
| E previous() |
[ Map ]
- 키(key)와 값(value)으로 구성된 엔트리 객체를 저장한다 (이때 키와 값은 모두 객체로 저장한다)
- 키는 중복저장을 허용하지 않고(Set방식) 값은 중복 저장이 가능하다(List방식)
- 키가 중복되는 경우, 기존에 있는 키에 해당 값을 덮어씌운다
-
구현 클래스로 HashMap, Hashtable, LinkedHashMap, Properties, TreeMap이 있다
- 주요 메소드
| 기능 | 메소드 | 설명 |
|---|---|---|
| 객체 추가 | V put(K key, V value) | 주어진 키와 값을 추가, 저장이 되면 값을 리턴 |
| 객체 검색 | V get(Object key) | 주어진 키의 값을 리턴 |
| boolean containsKey(Object key) | 주어진 키가 있는지 여부 | |
| boolean containsValue(Object value) | 주어진 값이 있는지 여부 | |
| Set<Map.Entry> entrySet() | 주어진 키와 값의 쌍으로 구성된 모든 엔트리 객체를 Set에 담아 리턴 | |
| boolean isEmpty() | 컬렉션이 비어 있는지 조사 | |
| int size() | 저장되어 있는 전체 객체 수를 리턴 | |
| Set keySet() | 모든 키를 Set 객체에 담아 리턴 | |
| Collenction values() | 모든 값을 Collection 객체에 담아 리턴 | |
| 객체 삭제 | void clear() | 저장된 엔트리객체를 삭제 |
| V remove(Object key) | 주어진 키와 일치하는 엔트리객체를 삭제 |
HashMap
Map<K, V> map = new HashMap<K, V>();
- Map 인터페이스를 구현한 대표 Map 컬렉션
- 키는 중복 저장을 허용하지 않지만 값은 중복을 허용한다
=> 동일한 키가 되는 조건은 hashCode()의 리턴값이 같고 , equals() 메소드의 결과가 true일 경우 이다 => 이러한 조건들 때문에 키타입은 hashCode()와 equals() 메소드가 재정의 되어있는 String 타입을 주로 사용한다
Hashtable
- HashMap과 동일한 내부 구조를 가지고 있다
- HashMap과 다른점은 스레드 동기화가 된 상태이기 때문에 Thread safe 속성을 지닌다
=> 동기화된 메소드로 구성되어있다 => 복수의 스레드가 동시에 Hashtable에 접근해 객체를 추가, 삭제 하더라도 스레드에 안전하다
Properties
- Hashtable의 하위 클래스이다
- 키와 값을 String 타입으로 제한한 Map 컬렉션이다
- 주로 프로퍼티(*.properties)파일을 읽어들일 때 사용한다
- 프로퍼티 파일이란
- 애플리케이션의 옵션정보, 데이터베이스 연결 정보, 다국어 정보를 기록한 텍스트 파일이다
- 애플리케이션에서 주로 변경이 잦은 문자열을 저장하여 관리하기 때문에 유지보수를 편하게 만들어준다
- 키와 값이
=기호로 연결되어 있는 텍스트 파일로 ISO 8859-1 문자셋으로 저장되고, 한글은 유니코드(Unicode)로 변환되어 저장된다
[ TreeMap 과 TreeSet ]
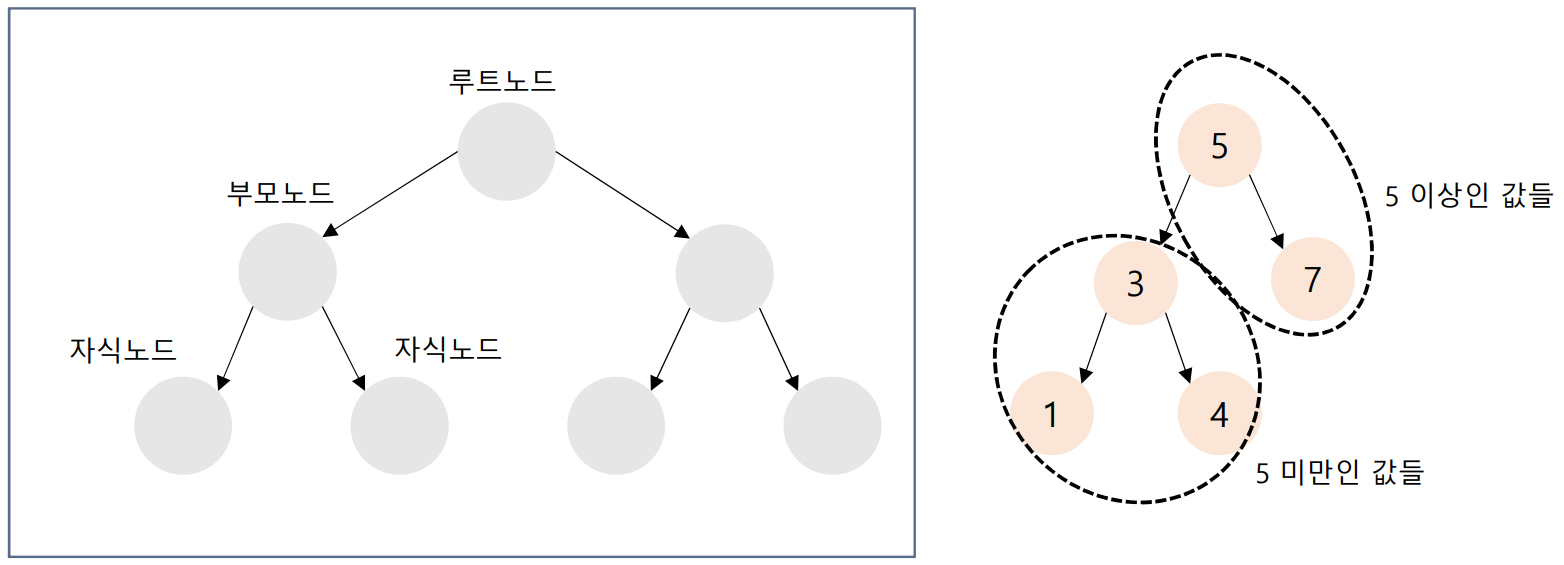
- 검색 기능을 강화시킨 컬렉션이다
- 계층 구조를 활용해 이진 트리 자료구조를 구현하여 제공한다
- 트리란 각 노드간 연결된 모양이 나무와 같다고 해서 붙여진 이름이다
TreeSet
- 이진 트리를 기반으로 한 Set 컬렉션으로, 왼쪽/오른쪽 자식 노드를 참조하기 위한 두개의 변수로 구성되어있다
- 정렬기능이 추가되었고 동일한 객체는 중복 저장하지 않는다
- 정렬된 순서대로 보관하며 정렬 방법을 지정 가능하다
- 범위 검색에 효과적이다
- 레드블랙트리 구조를 사용한다
- HashSet보다 성능상 느리지만 삽입과 동시에 정렬할 때 사용한다
TreeMap
- 이진 트리를 기반으로 한 Map 컬랙션으로, 키와 값이 저장된 Map.Entry를 저장하고 왼쪽/오른쪽 자식노드를 참조하기 위한 두개의 변수로 구성되어있다
TreeSet, TreeMap 정렬
- 오름차순(기본)
- TreeSet과 TreeMap의 key는 저장과 동시에 자동으로 오름차순 정렬된다
- 숫자(Integer, Double) 타입일 경우 값으로 정렬된다
- 문자열(String) 타입일 경우 유니코드로 정렬된다
-
정렬을 위해 java.lang.Comparable을 구현한 객체를 요구한다
=> Integer, Double, String 모두 Comparable 인터페이스를 통해 오름차순이 구현되어 있다 => 구현되어있지 않은 객체를 쓸 경우 ClassCastException이 발생한다 - 내림차순(따로 구현해야함)
- TreeSet, TreeMap 생성시 매개변수 생성자를 통해 재정렬이 가능하다
TreeSet<E> tSet = new TreeSet(Comparator<? super E> comparator); TreeMap<K, V> tMap = new TreeMap(Comparator<? super K> comparator); - 숫자(Integer, Double), 문자열(String) 타입을 제외한 Comparable을 상속 받는 객체인 경우 compareTo() 메소드의 오버라이딩 부분을 내림차순으로 변경한다
- TreeSet, TreeMap 생성시 매개변수 생성자를 통해 재정렬이 가능하다
[ Stack 과 Queue ]
Stack
Stack<E> stack = new Stack<E>();
Vector<E>를 상속받은 클래스로 후입선출(LIFO, Last In First Out) 자료구조를 가진다-
JVM Stack 메모리가 Stack구조로 되어 있다
-
주요 메소드
메소드 설명 E push(E item) 주어진 객체를 스택에 넣는다 E peek() 스택의 맨 위 객체를 가져온다 -> 객체를 스택에서 제거하지 않는다 E pop() 스택의 맨 위의 객체를 가져온다 -> 객체를 스택에서 제거한다
Queue
Queue<E> queue = new Queue<E>();
Collection<E>을 상속받은 클래스로 선입선출(FIFO, First In Firt Out) 자료구조를 가진다-
작업 큐나 메시지 큐가 Queue의 구조로 되어있다
- 주요 메소드
| 메소드 | 설명 |
|---|---|
| boolean offer(E e) | 주어진 객체를 넣는다 |
| E peek() | 가장 처음 추가된 객체를 하나 가져온다 -> 객체를 큐에서 제거하지 않는다 |
| E poll() | 거장 처음 추가된 객체를 하나 가져온다 -> 객체를 큐에서 제거한다 |
Deque
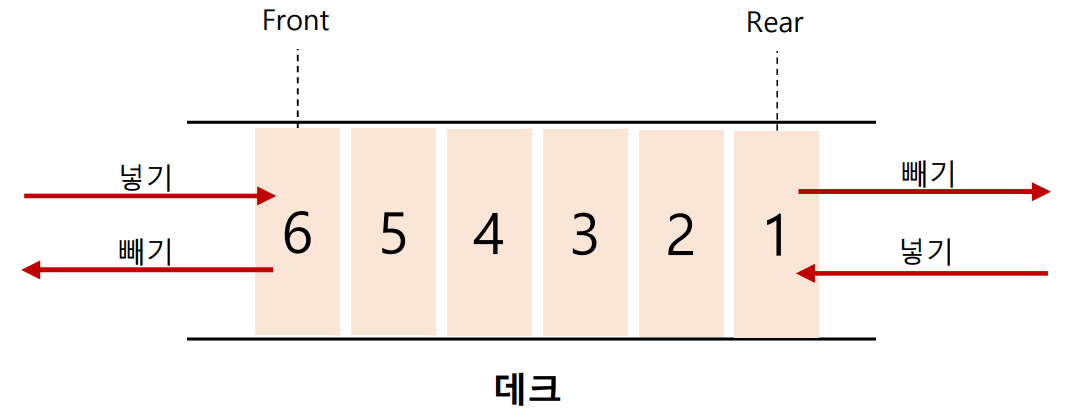
- 큐와 스택의 성질을 모두 가지고 있는 구조이다
-
검색과 같은 반복적인 문제에 특히 유용하다
- 주요 메서드
| 리턴 타입 | 메소드 | 설명 |
|---|---|---|
| boolean, void | push, offer, add(E e) | 해당 메소드 뿐만 아니라 메소드 뒤 First, Last를 붙여 앞 뒤에 주어진 객체를 넣는다. |
| E | peek, get() | 해당 메소드 뿐만 아니라 메소드 뒤 First, Last를 붙여 객체를 가져온다 -> 객체를 큐에서 제거하지 않는다 |
| E | poll, remove() | 해당 메소드 뿐만 아니라 메소드 뒤 First, Last를 붙여 객체를 하나 가져온다 -> 객체를 큐에서 제거한다 |
[ 동기화 ]
List<T> syncList = Collections.synchronizedList(list);
Map<K, V> syncMap = Collections.synchronizedMap(map);
Set<T> syncSet = Collections.synchronizedSet(set)
- Vector 와 Hashtalbe을 제외한 대부분의 컬렉션 클래스들은 싱글 스레드 환경에서 사용할 수 있도록 설계되었다
=> 멀티 스레드 환경에서 무결성을 보장하지 못한다 -
싱글 스레드 환경에 맞게 설계된 컬렉션 객체들을 동기화된 메소드로 래핑할 수 있도록 Collections가 메소드들을 제공한다
- Collections의 동기화 래핑 메소드
| 리턴타입 | 메소드 | 설명 |
|---|---|---|
| List |
synchronizedList(List |
List를 동기화된 List로 리턴 |
| Map<K, V> | synchronizedMap(Map<K, V> m) | Map을 동기화된 Map으로 리턴 |
| Set |
synchronizedSet(Set |
Set을 동기화된 Set으로 리턴 |
댓글남기기