
SQL(Structured Query Language)
SQL 이란
- 관계형 데이터베이스에서 데이터를 조회하거나 조작하기 위해 사용하는 표준 검색 언어이다
-
원하는 데이터를 찾는 방법이나 절차를 기술하는 게 아닌 조건을 기술하여 작성한다
- 주요 용어
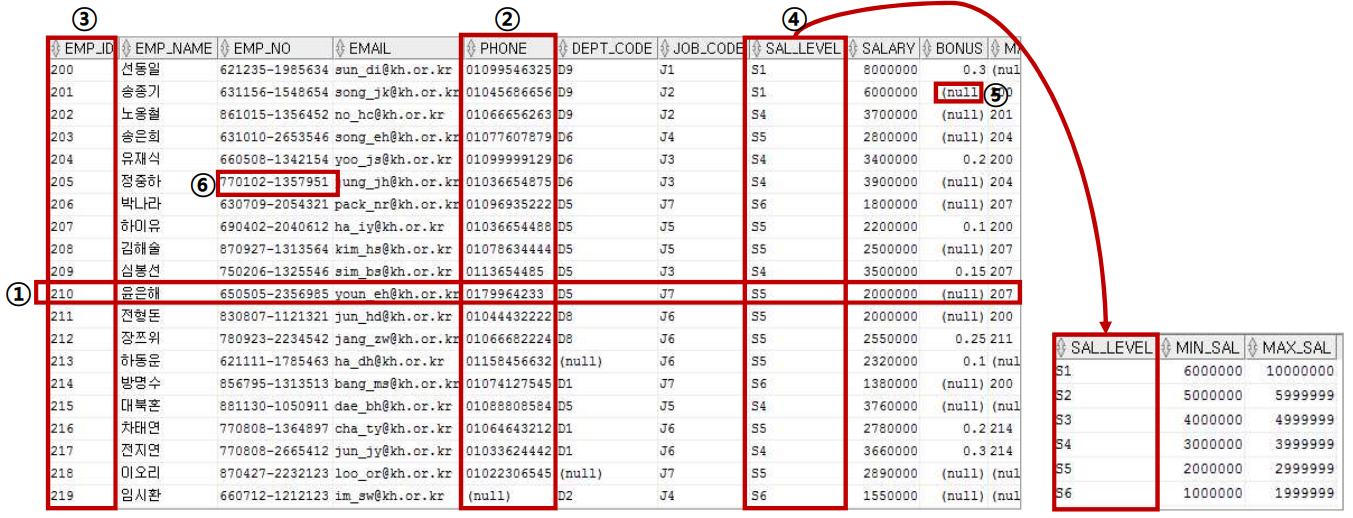
- 행(Row), 튜플
- 컬럼, 도메인
- 기본키(Primary Key)
- 외래키(Foreign Key)
- Null
- 컬럼값, 속성값
-
분류
분류 용도 명령어 DQL (Data Query Language) 데이터 검색 SELECT DML (Data Manipulation Language) 데이터 조작 INSERT(추가), UPDATE(수정), DELETE(삭제) DDL (Data Definition Language) 데이터 정의 CREATE(생성), DROP(삭제), ALTER(수정/삭제/추가) DCL (Data Control Language) 데이터 제어 GRANT(권한부여), REVOKE(권한해제) TCL (Transaction Control Language) 트랜잭션 제어 COMMIT(정상저장), ROLLBACK(취소) - SLELCT를 위처럼 DQL로 따로 빼기도 하지만 대부분 DML로 포함시킨다
주요 데이터 타입
| 데이터 타입 | 하위 데이터 타입 | 설명 |
|---|---|---|
| NUMBER | 숫자 | |
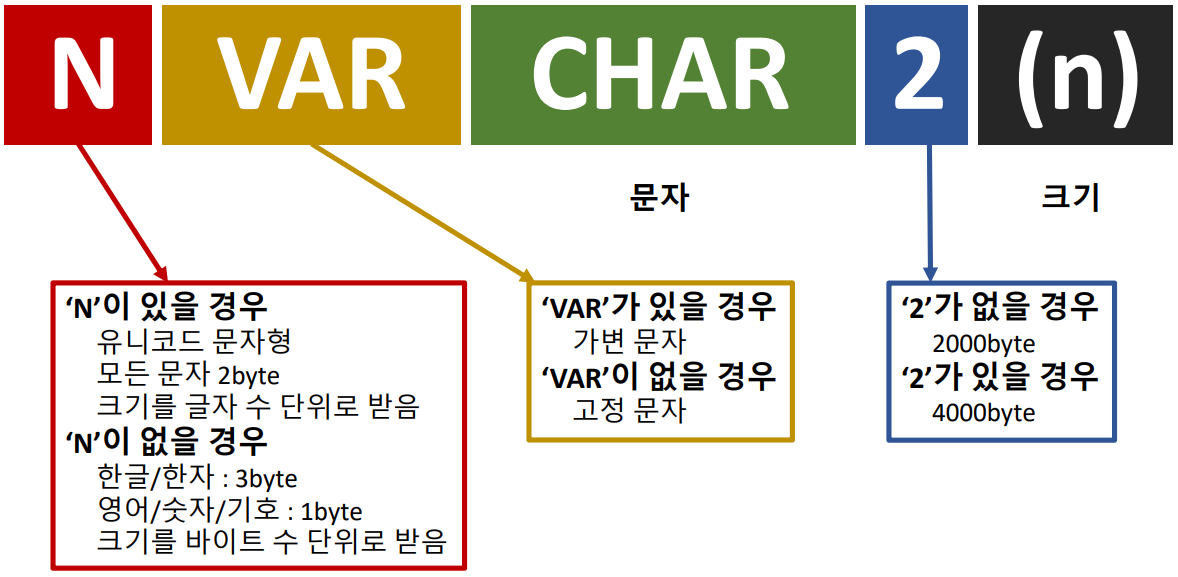
| CHARACTER | CHAR | 고정길이 문자(최대 2000바이트) |
| VARCHAR2 | 가변길이 문자(최대 4000바이트) | |
| LONG | 가변길이 문자(최대 2기가 바이트) | |
| DATE | 날짜 | |
| LOB | CLOB | 가변길이 문자(최대 4기가 바이트) |
| BLOB | Binary Data |
[ NUMBER ]
-
NUMBER[ ( P [ , S ] ) ]- [ ] : 생략가능
- P : 표현할 수 있는 전체 숫자 자리 수 (1 ~ 38)
- S : 소수점 이하 자리 수 (-84 ~ 127)
- 정수/실수 관계 없이 사용하는 자료형이다
[ CHARACTER ]
-
공통사항
- [ ] : 생략가능
- SIZE : 포함될 문자(열)의 크기
=> 숫자/영문자/특수문자 : 1글자당 1byte
=> 한글/한자 : 1글자당 3byte - 데이터는 ‘‘를 사용하여 표기하고 대·소문자를 구분
-
CHAR( SIZE [ ( byte | char ) ]- 지정한 크기보다 작은 문자(열)가 입력되면 남는 공간은 공백으로 채움
=> 고정된 길이를 가진다 - 최대 2000byte 까지 저장가능
- 주로 들어올 값의 글자수가 정해져 있을 경우 사용한다
=> ex) 성별 , 주민번호 등 - 나중에 java 등과 연동했을 때 안에 공백이 포함되어있다면 뜻하지 않은 오류가 발생할 가능성이 높아서 아래 VARCHAR 활용을 추천한다
- 지정한 크기보다 작은 문자(열)가 입력되면 남는 공간은 공백으로 채움
-
VARCHAR2( SIZE [ ( byte | char ) ]- 크기가 0인 값은 NULL로 인식
- 공간대비 저장되는 글자가 크다면 오류발생
- 최대길이 4000byte 까지 가능하다
- VAR는 가변, 2는 2개를 의미한다
- 주로 들어온 값의 글자수가 정해져 있지 않은경우 사용한다
- 매개변수에 CHAR가 들어온 경우 byte단위로 데이터를 체크하지 않고 문자의 갯수로 체크한다
-
NVARCHAR- 문자열의 바이트가 아닌, 문자 갯수 자체를 길이로 취급한다
- 유니코드를 지원하기 위한 자료형이다
[ DATE ]
DATE- 일자(세기/년/월/일) 및 시간(시/분/초) 정보를 관리한다
- 기본적으로 화면에 년/월/일 정보만 표기한다
- 날짜 연산 및 비교 가능하다
| 연산 | 결과 타입 | 설명 |
|---|---|---|
| 날짜 + 숫자 | DATE | 날짜에서 숫자만큼 며칠 후 |
| 날짜 - 숫자 | DATE | 날짜에서 숫자만큼 며칠 전 |
| 날짜 - 날짜 | NUMBER | 두 날짜의 일수 차 |
| 날짜 + 숫자/24 | DATE | 날짜 + 시간 |
SELECT문
- 데이터를 조회한 결과를 Result Set이라고 하는데 SELECT구문에 의해 반환된 행들의 집합을 의미한다
- Result Set은 0개 이상의 행이 포함될 수 있고 특정 기준에 의해 정렬 가능하다
- 한 테이블의 특정 컬럼, 행, 행/컬럼 또는 여러 테이블의 특정 행/컬럼 조회가 가능하다
[ 표현법 ]
[ SELECT문 구조 및 실행순서 ]
5. SELECT [DISTINCT] 조회하고자 하는 칼럼명 나열 / * / 리터럴 / 산술연산식 / 함수 / 별칭부여
1. FROM 조회하고자 하는 테이블명 / 인라인쿼리 / 가상테이블(DUAL)
2. WHERE 조건식 (그룹함수를 사용할 수 없음)
3. GROUP BY 그룹 기준에 해당하는 칼럼명 / 함수식
4. HAVING 그룹 함수식에 대한 조건식
6. ORDER BY 정렬기준용 컬럼명 / 별칭 / 컬럼의 순번 [ASC / DESC] [NULLS FIRST / NULLS LAST];
-
SELECT
- 조회하고자 하는 컬럼명을 기술한다
- 여러 컬럼을 조회하는경우 쉼표로 구분하며 전체 컬럼 조회는 쉼표 대신 * 기호를 사용한다
- 조회 결과는 기술한 컬럼 명 순으로 나열된다
- DISTINCT : 중복행을 제거하는 옵션
-
FROM
- 조회 대상 컬럼이 포함된 테이블명을 기술한다
-
WHERE
- 행을 선택하는 조건을 기술한다
- 여러개의 제한 조건을 걸 수 있으며 각각 논리 연산자로 연결시킨다
- 제한 조건을 만족시키는 행들만 Result Set에 포함된다
- 조회하고자 하는 테이블에 특정 조건을 제시해서 조건을 만족하는 데이터만을 조회하고자 할때 사용한다
- 그룹함수를 사용할 수 없다
-
GROUP BY
- 그룹을 묶어줄 기준을 제시 할 수 있는 구문으로 그룹함수와 함께 쓰인다
- 데이터들을 원하는 그룹으로 나눌 때 사용한다
- 그룹함수는 단 한개의 결과값만 산출하기 때문에 그룹이 여러개일 경우 오류가 발생한다
=> 따라서 여러개의 결과값을 산출하기 위해 그룹함수가 적용될 그룹의 기준을 기술하여 사용하는 것
-
HAVING
- GROUP BY절과 함께 쓰이며 그룹에 대한 조건을 제시하고자 할 때 사용된다
- WHERE절은 SELECT에 대한 조건을 제시하고 HAVING절은 GROUP BY절에 대한 조건을 제시한다
- 그룹 함수를 사용할 수 있다
-
ORDER BY
- 특정 컬럼의 데이터를 중심으로 오름차순/내림차순 정렬을 시킨다
- 표현법 :
ORDER BY [칼럼명/별칭/컬럼순번] [ASC/DESC](생략가능) [NULLS FIRST/NULLS LAST](생략가능) - ASC : 오름차순 12345 (기본값)
- DESC : 내림차순 54321 (최신순 정렬)
- NULLS FIRST : null 값들을 가장 먼저 정렬
- NULLS LAST : null 값들을 가장 뒤에 정렬
구분 오름차순(ASC) 내림차순(DESC) 숫자 작은 값부터 정렬 큰 값부터 정렬 문자 사전 순서대로 정렬 사전 순서 반대로 정렬 날짜 빠른 날짜 순서로 정렬 늦은 날짜 순서로 정렬 NULL 가장 마지막에 나옴 가장 먼저 나옴 -
실행순서
- FROM -> WHERE -> GROUP BY -> HAVING -> SELECT -> ORDER BY
=> SQL은 코드가 위에서부터 실행되지 않고 논리적인 흐름에 따라, 실행되는 순서가 섞여있으니 주의
- FROM -> WHERE -> GROUP BY -> HAVING -> SELECT -> ORDER BY
[ 활용 ]
-
컬럼 값 산술 연산
SELECT EMP_NAME, SALARY * 12, (SALARY + (SALARY*BONUS)) * 12- 컬럼 값에 대해 산술 연산(+ - / *)을 기술하여 결과를 조회할 수 있다
- 산술연산 과정에서 null값이 존재할 경우 산술 연산 결과마저도 null이 된다
-
컬럼 별칭
SELECT EMP_NAME AS 이름, SALARY*12 "연봉(원)"- 컬럼의 별칭을 지을 수 있다
- 표현법 : 컬럼명 AS 별칭, 컬럼명 AS “별칭”, 컬럼명 별칭, 컬럼명 “별칭”
- 위처럼 컬럼명 뒤에 기술하여 별칭을 짓는다
=> AS와 쌍따옴표는 생략 가능 (공백으로 구분) => 숫자/특수문자가 포함되는 경우에는 꼭 쌍따옴표를 사용해야 한다 => SQL에서 홀따옴표와 쌍따옴표는 기능이 다르니 주의할 것, 꼭 쌍따옴표로 표기해야 한다- (‘)홑따옴표 : 문자열을 감싸주는 기호
- (“)쌍따옴표 : 컬럼명 등을 감싸주는 기호(식별자로 봄)
- SELECT 절에서 부여한 별칭은 WHERE 절에서 사용할 수 없다 (WHERE 절부터 실행되기 때문)
-
리터럴
SELECT EMP_ID, SALARY, '원' AS 단위- 임의로 지정한 문자열(‘‘)을 SELECT절에 기술하면 실제 그 테이블에 존재하는 데이터처럼 활용및 조회가 가능하다
=> 문자나 날짜 리터럴은 ‘’ 기호를 사용한다 - 리터럴은 Result Set의 모든 행에 동일한 내용(위에서 임의로 기술한 문자열 그대로)으로 반복 표시된다
- 임의로 지정한 문자열(‘‘)을 SELECT절에 기술하면 실제 그 테이블에 존재하는 데이터처럼 활용및 조회가 가능하다
-
DISTINCT
SELECT DISTINCT JOB_CODE- 칼럼에 중복된 값을 딱 한번만 조회하고자 할 때 사용한다
- 칼럼에 포함된 데이터 중 중복값을 제외하고 동일데이터는 1회만 표시한다
- SELECT 절에 DISTINCT 구문은 1회만 기술 가능하다
=> 한번 불리면 불러온 칼럼들 모두를 한줄(튜블)로 취급해서 중복을 제거한다 => 하나의 칼럼에서만 중복을 제거하는 것이 아니라는 것을 주의
-
||연결 연산자-- 컬럼과 컬럼 연결 SELECT EMP_ID || EMP_NAME || SALARY -- 컬럼과 리터럴을 연결 SELECT EMP_NAME || '의 월급은' || SALARY || '원 입니다.'- 여러 컬럼을 하나의 컬럼인 것 처럼 연결 가능하다
- 컬럼과 리터럴을 연결 할 수도 있다
연산자
[ 논리 연산자 ]
| 연산자 | 설명 |
|---|---|
| AND | 여러 조건이 동시에 TRUE일 경우에만 TRUE값 반환 |
| OR | 여러 조건들 중에 어느 하나의 조건만 TRUE이면 TRUE값 반환 |
| NOT | 조건에 대한 반대 값으로 반환(NULL 제외) |
[ 비교연산자 ]
- 연산자 종류
| 연산자 | 설명 |
|---|---|
| = | 같다 |
| > , < | 크다 / 작다 |
| >= , =< | 크거나 같다 / 작거나 같다 |
| <> , != , ^= | 같지 않다 |
| BETWEEN AND | 특정 범위에 포함되는지 비교 |
| LIKE / NOT LIKE | 문자 패턴 비교 |
| IS NULL / IS NOT NULL | NULL 여부 비교 |
| IN / NOT IN | 비교 값 목록에 포함/미포함 되는지 여부 비교 |
- 연산자 우선순위
| 우선순위 | 연산자 |
|---|---|
| 0 | ( ) |
| 1 | 산술 연산자 |
| 2 | 연결 연산자 |
| 3 | 비교 연산자 |
| 4 | IS NULL , LIKE, IN |
| 5 | BETWEEN AND |
| 6 | 논리 연산자 – NOT |
| 7 | 논리 연산자 – AND |
| 8 | 논리연산자 – OR |
NOT은 자바에서의!논리부정 연산자처럼 결과값을 뒤집는다- 표현식 사이의 관계를 비교하기 위해 사용한다
- 비교결과는 논리결과 (TRUE/FALSE/NULL) 중 하나가 된다
- 단 비교하는 두 컬럼 값/표현식은 서로 동일한 데이터 타입이어야 한다
BETWEEN AND
WHERE SALARY BETWEEN 3500000 AND 6000000;
WHERE SALARY NOT BETWEEN '90/01/01' AND '03/01/01';
- 몇 이상 몇 이하인 범위에 대한 조건을 제시할 때 사용한다
- BETWEEN으로 DATE형식 간에도 비교가 가능하다
LIKE
WHERE EMP_NAME LIKE '전%';
WHERE EMP_NAME LIKE '_지_';
WHERE EMAIL LIKE '__\_%' ESCAPE '\';
- 표현법 :
컬럼명 LIKE '특정 패턴' - 비교하고자 하는 컬럼 값이 내가 지정한 특정 패턴에 만족될 경우 true를 리턴한다
-
특정 패턴 부분에
%와_를 와일드 카드로 사용한다 -
%- 0개 이상의 임의의 문자열을 의미한다
- ‘문자%’ : 컬럼 값중에 ‘문자’로 시작하는 것을 조회
- ‘%문자’ : 컬럼 값중에 ‘문자’로 끝나는 것을 조회
- ‘%문자%’ :컬럼 값중에 ‘문자’가 포함되는 것을 조회
-
_- 문자 1개를 의미한다
- ‘_문자’ : 컬럼 값중에 ‘문자’ 앞에 1글자가 존재하는 경우 조회
- ‘__문자’ : 컬럼값중에 ‘문자’ 앞에 2글자가 존재하는 경우 조회
- ‘문자_’ : 컬럼값중에 ‘문자’ 뒤에 1글자가 존재하는 경우 조회
- 위와 같은 식으로
_를 앞뒤로 여러개 이어붙여 조건을 검사할 수 있다
-
ESCAPE OPTION
- 표현법 :
컬럼명 LIKE '특정 패턴' ESCAPE '문자열' - 와일드 카드 문자와 패턴의 특수문자가 동일한 경우 어떤것을 패턴으로 결정하는지 구분하지 못하게 되는 것을 방지하고자 사용한다
- ESCAPE ‘문자열’ -> ‘문자열’ 바로뒤에 있는 한글자는 와일드카드로 인식하지 않겠다는 뜻
- ‘문자열’에는 사용하고 싶은 문자들을 숫자에 상관없이 자유롭게 지정 가능하다
- 표현법 :
IS NULL과 IS NOT NULL
WHERE DEPT_CODE IS NULL AND BONUS IS NOT NULL;
- null 여부를 비교하는 연산자
- IS NULL : 컬럼 값이 null인 경우 true를 반환
- IS NOT NULL : 컬럼 값이 NULL 이 아닌 경우 true를 반환
IN
WHERE DEPT_CODE IN ('D6', 'D8', 'D5');
- 비교대상 칼럼 값에 내가 제시한 목록 중 일치하는 값이 있는지 판단한다
- 표현법 :
컬럼명 IN(값, 값, 값, 값, ...) - = 과 AND를 써도 동일한 조건검사를 할 수 있지만 그 가짓수가 많을때 IN을 쓰면 코드가 훨씬 간결해진다
댓글남기기